Introduction
Most enterprise RAG projects work in a demo and break in production. The cause is not the language model. It is everything around it: connectors that drop permissions, chunking that destroys tables and charts, single-shot retrieval that cannot handle multi-hop questions, and the absence of evaluation. Microsoft's GraphRAG research showed grounding the same LLM in a knowledge graph moved accuracy on multi-hop reasoning from 16.7% to 56.2%, a 3.4x improvement. Cross-encoder reranking adds another 33% to 40% retrieval accuracy for roughly 120 ms of added latency. The 2026 enterprise RAG stack is no longer a linear pipeline. It is an agentic, permission-aware, hybrid retrieval system that measures its own faithfulness before shipping an answer. This guide covers every failure mode worth knowing and the architecture choices that close them.
Key Takeaways
- Modern enterprise RAG is agentic, not linear. The system reasons about which source, tool, or index to consult before retrieving.
- Vector search alone is no longer the default. Hybrid retrieval (BM25 + dense + reranker) and GraphRAG for multi-hop questions are now table stakes.
- Cross-encoder reranking is the single highest-ROI addition to most production RAG systems, delivering 33% to 40% accuracy improvement at 120 ms p50 latency.
- If you cannot measure faithfulness, answer relevance, and context precision, you do not have a production RAG system. RAGAS and TruLens are the practitioner defaults.
- Multimodal RAG matters because enterprise documents are not text. Charts, tables, and layout carry the answer in financial reports, ESG disclosures, claims, and contracts.
- Permissions must be enforced at query time at the index layer, not as a post-filter on retrieved chunks. Anything else leaks.
Why this guide exists
The first wave of enterprise RAG content treated it as a tidy pipeline: chunk, embed, retrieve, generate. The 2026 production stack does not look like that anymore. Practitioners have learned which steps actually break the system, which fixes generalize, and which 2024-era assumptions to throw out.
This is a consolidated reference for the people building or buying enterprise RAG: CIOs, CTOs, AI platform leads, and the engineers behind them. We cover the failure modes (with the data), the architecture pieces that resolve them, and the questions to ask before committing to a build, a vendor, or a hybrid. Throughout, we link to the deeper Atolio posts on each topic so you can drop into the level of detail you need.
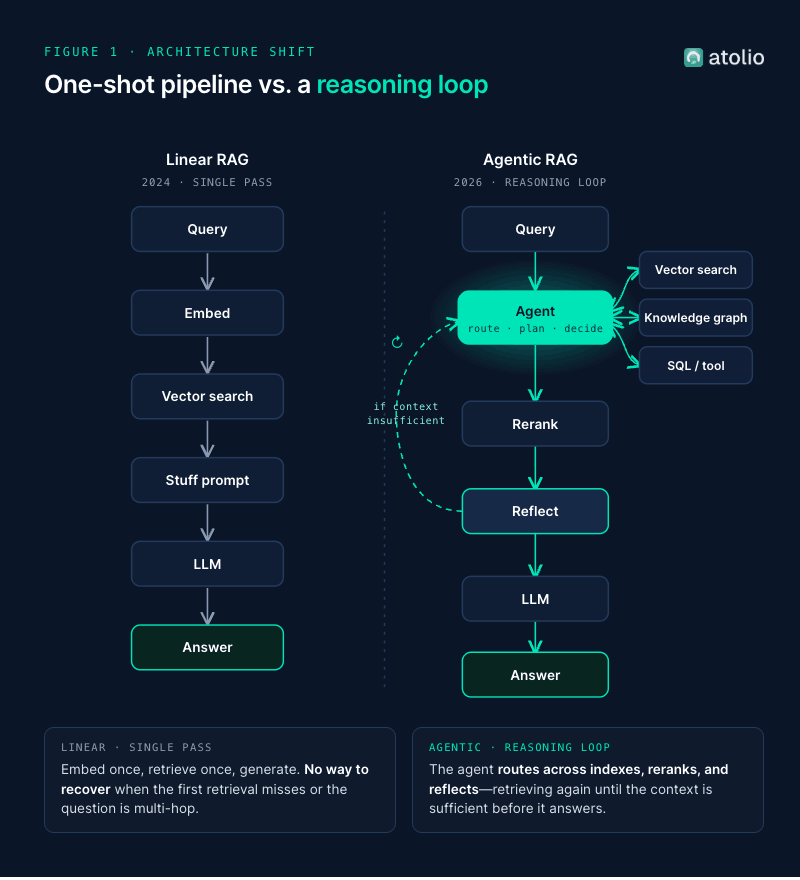
How has enterprise RAG architecture changed since 2024?
The biggest shift is from one-shot retrieval to reasoning-driven retrieval. A 2024 RAG system did this: embed query, top-k search, stuff results into a prompt, generate. A 2026 system does this: classify the query, route to the right tools (vector index, knowledge graph, SQL, code search), retrieve in stages, rerank, optionally reflect, then generate. The orchestration layer is now where most of the engineering goes.
The other shift is measurement. In 2024, most teams shipped on vibes. In 2026, teams that ship to production have an evaluation harness running RAGAS or TruLens on a labeled set, and they refuse to deploy regressions on faithfulness or context precision.
Two specific moves are visible across the production-grade systems we see:
- Retrieval became multi-modal and multi-index. Vector-only retrieval lost ground to hybrid retrieval over text, structured data, and document images.
- Single-pass became multi-pass. A reranker on the top-100, plus an optional reflection step, became the difference between a 60% answer-correct rate and an 85% rate.
We covered the architecture-level mechanics in Assembling and evolving an enterprise RAG platform. The rest of this guide drills into the failure points in order of how often they kill a project.
What are the biggest enterprise RAG challenges in 2026?
Eight challenges account for most production failures. They are interconnected, and a fix in one usually requires changes elsewhere.
Each section below covers one of these in working order.
1. Why is data source diversity the first thing that breaks?
A useful answer engine has to draw on every place work actually happens. In a typical large enterprise that is SharePoint, Microsoft Teams, Outlook, Slack, Confluence, Notion, Google Drive, Jira, GitHub, Salesforce, Zendesk, ServiceNow, and a long tail of departmental tools. Each one ships a different API (REST, gRPC, GraphQL), a different permission model, a different rate limit, and a different update mechanism.
Building connectors is a real software project, not a weekend script. And the answers to many questions live in more than one place. A "summary of customer Acme" pulls from Salesforce account notes, recent Zendesk tickets, the active Slack channel, and the last QBR deck in Google Drive. An "AI assistant" bolted onto a single tool, by design, cannot see the rest. We went deep on this in The diversity of data sources for RAG.
2. Why does text-only chunking fail on real enterprise documents?
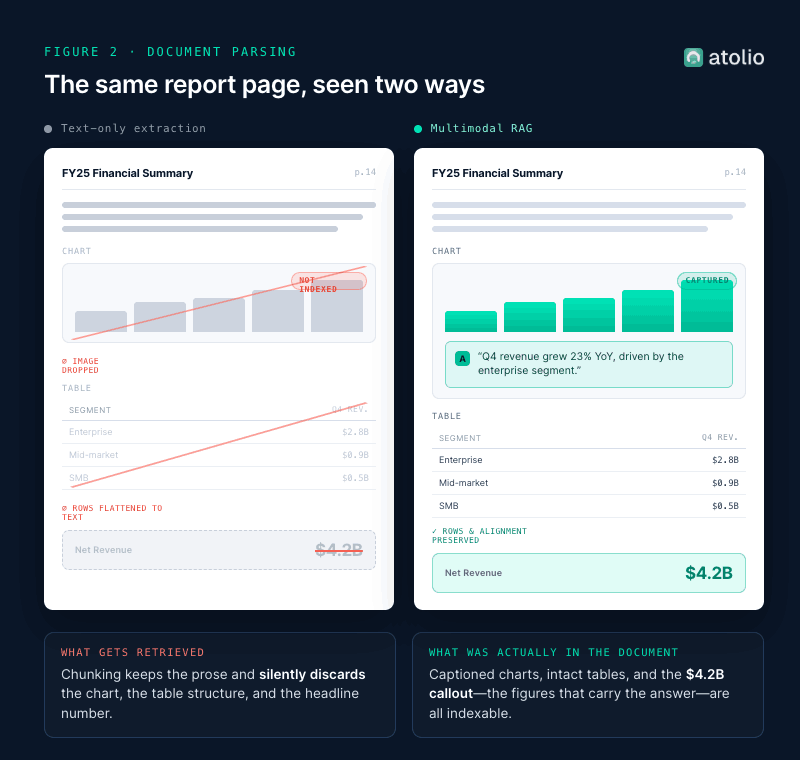
Most production RAG systems were built on the assumption that documents are text. Enterprise documents are not. Financial reports, ESG disclosures, insurance claims, medical forms, contracts, and research papers carry meaning in tables, charts, diagrams, and layout. A chart axis, a footnote, or the geometry of a table can hold the answer. Standard text extraction strips it.
This is the gap multimodal RAG closes. Three architectures dominate practical deployments in 2026:
- Caption-and-index. A vision-language model writes a natural-language summary of each chart or image. The summary gets indexed alongside the surrounding text. Cheapest, often good enough.
- Unified vision embeddings. Models like Cohere Embed 4 and voyage-multimodal-3.5 embed images and text into the same vector space. One index, one retrieval pass.
- Page-as-image with late interaction. Models like ColPali and ColQwen treat each rendered page as the unit of retrieval. Strong on visually dense documents, more expensive to store.
The practical answer for most enterprises is to start with caption-and-index for charts and tables, then move to unified embeddings as visual content volume grows. A team that ignores this and runs pure text RAG on a corpus of financial reports will silently lose a large fraction of the signal.
3. What is the right way to normalize and chunk enterprise data?
Diversity of sources means diversity of text and metadata. A well-tuned search platform wants uniform chunks, a normalized schema, and well-formed metadata. Your ingestion pipeline has to assemble and batch data, map source fields to a common schema, and push everything into the engine cleanly.
A few rules that hold up in production:
- Group sources into classes (documents, tickets, messages) and drive each class toward a shared schema with common fields (title, author, date, people involved, body text).
- Control text length actively. A Slack message and a 10-page Google Doc cannot be ranked against each other without normalization. BM25 cares about length. Dense embeddings care about chunk boundaries.
- Preserve structure in chunk boundaries (heading, paragraph, list item, table cell) rather than splitting on character count. Layout is signal.
- Carry rich metadata through every step: ACLs, source, owner, last-modified, document class, sensitivity label.
We covered the implementation details in Normalizing enterprise data for effective search and RAG. If your team is building this themselves, count on it taking longer than you think. The dynamic-mapping shortcuts in ElasticSearch and OpenSearch feel fast in a prototype and become expensive in production.
4. Hybrid search, cross-encoder reranking, and GraphRAG: which retrieval matters?
Vector search alone is not enough. Three retrieval techniques together carry production-grade systems.
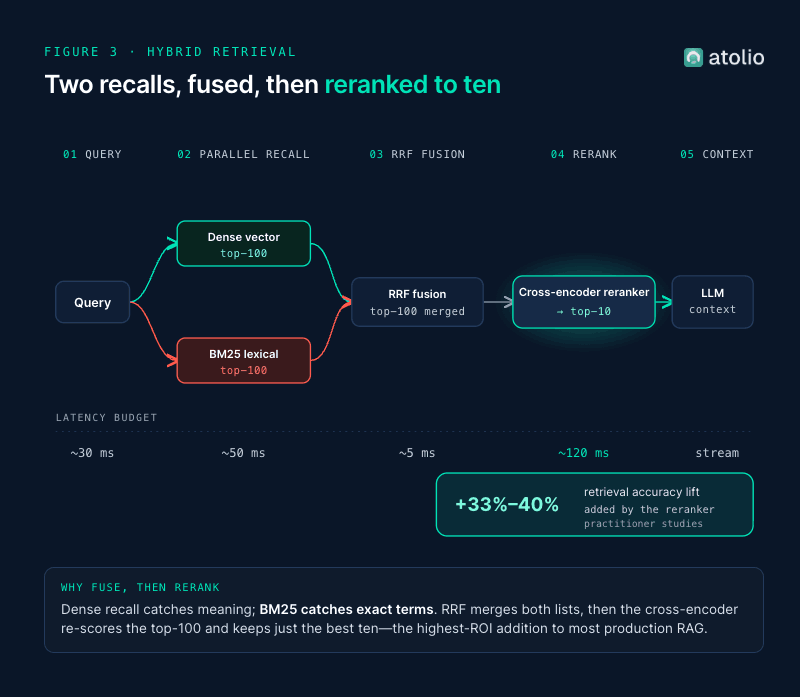
Hybrid search (BM25 + dense + fusion)
Dense vectors are good at semantic matching. BM25 is good at exact terms, IDs, and acronyms. Most enterprise queries need both. Run them in parallel and fuse the result sets with Reciprocal Rank Fusion (RRF). This is now the baseline, not the advanced move.
Cross-encoder reranking
A bi-encoder retrieval call returns the top 100 candidates fast but imprecisely. A cross-encoder jointly attends over each query-document pair and reranks the top 100 down to a precision-tuned top 10. The lift is large: practitioner studies report +5 to +15 NDCG@10, with end-to-end RAG accuracy gains of 33% to 40% for roughly 120 ms p50 added latency. Cohere Rerank 4 (Pro and Fast) is the default for most teams because integration cost is low; open-source options (BGE Reranker, Jina Reranker, FlashRank) are competitive and run locally.
If you have a production RAG system without a reranker, this is almost certainly your highest-ROI addition. We use this multi-phase pattern in Atolio: BM25 + dense recall, fused, then cross-encoder rerank on the top candidates.
GraphRAG for multi-hop reasoning
Pure vector search treats every retrieval as a similarity lookup. It works for “What is our refund policy?” It fails for “How is Person A connected to Event B through Organization C?” These multi-hop questions are common in finance, legal, life sciences, and intelligence work.
GraphRAG indexes the corpus into a knowledge graph of entities and relationships, then traverses the graph at query time. Microsoft's original paper showed an LLM grounded in a knowledge graph moved from 16.7% to 56.2% accuracy on global summarization tasks. Newer LazyGraphRAG variants reduce indexing cost to roughly 0.1% of the full-graph approach, which removes the historical objection that graphs were too expensive to maintain.
The 2026 consensus is not “graphs replace vectors.” It is hybrid: vectors for breadth and recall, graphs for the multi-hop questions where vector search alone is structurally incapable.
5. What is Agentic RAG, and when does an enterprise actually need it?
Agentic RAG replaces the linear “retrieve then generate” pipeline with an agent that reasons about how to answer the question. Given a query, the agent decides what to retrieve, from which source, in what order, and whether the retrieved context is sufficient before responding. If it is not, the agent can run another retrieval, switch tools, or escalate.
Five patterns cover most production agentic systems:
- Router. Pick the right tool or index based on query intent.
- ReAct. Interleave reasoning and tool calls.
- Plan-and-execute. Decompose the question, execute steps, synthesize.
- Multi-agent retrieval. Specialized agents for different sources.
- Self-RAG / reflection. Critique retrieved context and re-retrieve if it falls short.
The right default is hybrid. Classic RAG handles the majority of queries faster and cheaper. Agentic RAG is the escalation path for questions that cannot be answered in a single retrieval pass. Agentic loops typically consume 3x to 10x the tokens of classic RAG, so the quality lift has to justify the spend on the workloads where it actually shows up: multi-hop questions, cross-system synthesis, comparisons across silos.
LangGraph and LlamaIndex Workflows are the two production-ready orchestration frameworks. The choice is less about the framework and more about whether your platform supports tool calling, state, retries, and observability natively.
6. How do permissions and governance actually work in production?
Permissions are where most enterprise RAG systems quietly fail compliance review. The wrong way is to retrieve everything and filter afterward: chunks are already in memory, model context, and logs by the time you exclude them. The right way is to enforce permissions at the index layer at query time so unauthorized content is never returned in the first place.
A production-grade permission model has to handle the following:
- ACL replication from each source. SharePoint, Confluence, Google Drive, Slack channels, Jira projects all have their own permission models. Replicate them, do not approximate them.
- Identity reconciliation. The same person has different accounts and aliases in different tools. Without a canonical identity, you over-permission or under-permission.
- Real-time sync. Permission changes in source systems must propagate to the index within minutes, not on a nightly rebuild.
- Group and role resolution. Nested groups and dynamic roles have to be resolved against the IdP (Okta, Microsoft Entra ID, Google Workspace, Keycloak), not flattened.
- Sensitivity-label awareness. Microsoft Purview and Google Workspace sensitivity labels should drive ingestion-time exclusion.
This is one area where Atolio's architecture is opinionated. ACLs are replicated from every source, identities are unified via SSO and OIDC, and unauthorized content is excluded at the index level before it ever reaches a user or a model. More details are on Atolio's security page and our deep dive on permissions and privacy in an enterprise RAG platform.
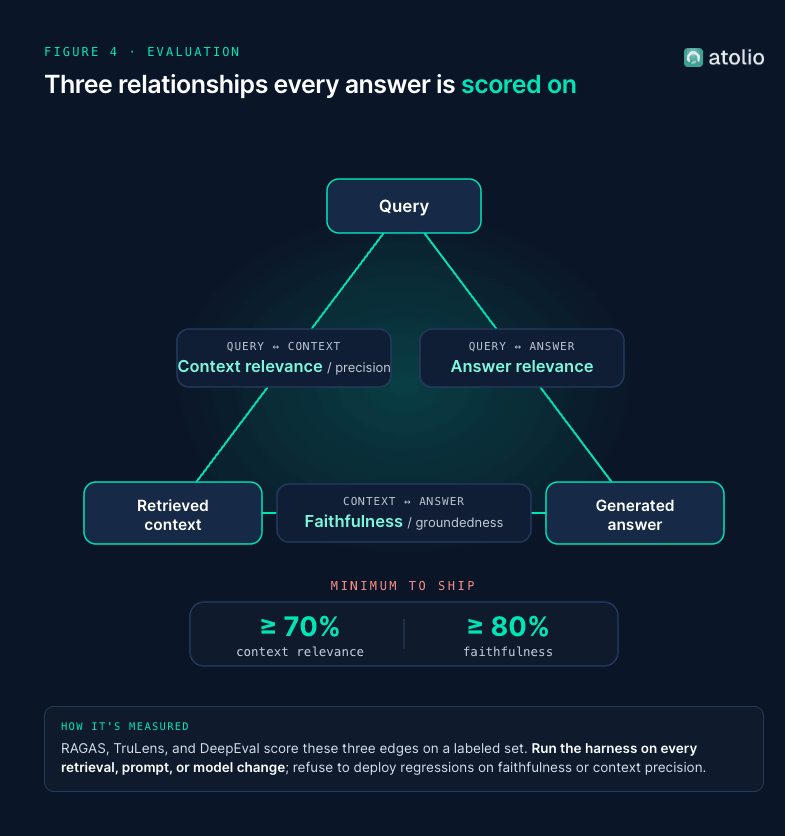
7. How do you measure whether a RAG system actually works?
Practitioners now treat evaluation as the line between a prototype and a production system. If you cannot measure faithfulness and answer relevance on a labeled set, you cannot tell whether your last change helped or hurt.
The three open-source frameworks that matter:
The four metrics every production RAG system should be tracking:
- Faithfulness / groundedness. Does the generated answer reflect only what was retrieved, with no unsupported claims?
- Answer relevance. Does the answer address the question the user actually asked?
- Context precision. Are the retrieved chunks relevant?
- Context recall. Did retrieval surface all the relevant chunks?
A practical baseline: target above 70% context relevance and above 80% faithfulness on a representative labeled set before shipping to users. Add agentic-specific metrics if you have agents in the loop: tool-selection accuracy, plan-decomposition quality, loop-termination rate, and p50 / p90 / p99 latency.
Evaluation is not a one-time exercise. The labeled set has to grow with the system, and every retrieval or prompt change should run against it before merge.
8. How do you pick the right engine, embedding model, and LLM?
Component selection is where teams burn weeks. The framework that holds up:
Search engine. You need an engine that does dense vectors, sparse text, hybrid fusion, and reranking natively, not by federating across separate systems. Vespa, OpenSearch with the right plugins, and a small set of commercial engines clear this bar. Atolio is built on Vespa for exactly this reason: late-interaction models, multi-vector indexing, and multi-phase ranking happen in one engine without a “retrieval tax.”
Embedding model. The default for English-only corpora is a strong dense model (Cohere Embed v4, OpenAI text-embedding-3-large, or an open-source equivalent like BGE). For multilingual or multimodal corpora, choose a model that handles both, or run separate indices. Re-embedding is expensive; pick once and version carefully.
LLM. This is the one place to stay flexible. Models improve every quarter. Your platform should let you swap LLMs without rebuilding everything. The right pattern is to expose model choice as a configuration, support hosted (OpenAI, Anthropic, Azure OpenAI, Bedrock) and self-hosted (Llama 3.x, Qwen, Mistral) models, and let security and cost teams choose per use case. Atolio supports this pattern by design: hosted LLMs for general use, locally-hosted models when data sensitivity demands no data leaves the customer cloud.
Deployment model. For regulated industries and any organization where corporate data cannot leave the customer cloud, the platform has to run in the customer's VPC (AWS, Azure, GCP, GovCloud) or on-prem. This is non-negotiable in defense, finance, healthcare, and most Fortune 500 procurement. It is also how Atolio is deployed.
What are the most common failure points in production RAG systems?
Independent of architecture, six failure modes recur. Watching for them is more useful than memorizing best practices.
- Ingestion drops. A connector silently misses updates. The system answers from stale state.
- Permission leakage. A post-filter approach lets a chunk reach the model context before exclusion.
- Chunking destroys structure. Tables lose row alignment; lists lose order; headings detach from content.
- Retrieval saturates. Top-k stays the same, but precision drops as the corpus grows. No reranker, no recovery.
- Prompt brittleness. A working prompt breaks after a model update because nothing pinned the behavior.
- No evaluation. Changes are shipped on vibes. Regression hits production.
The fix for most of these is upstream: better connectors, ACL replication at the index layer, structure-aware chunking, a reranker on the top-100, prompt version control, and an evaluation harness that runs on every change.
The DIY trap: what teams underestimate
Most teams that build their own enterprise RAG underestimate the “plumbing” layer. The orchestration that ties together hybrid search, reranking, agentic reasoning, permission enforcement, observability, and evaluation is the actual engineering challenge. The components are available, often as open source. The integration is not.
A working production system has to do all of the following at the same time:
- Sync ACLs from every source within minutes.
- Re-embed and re-index updated documents without rebuilding.
- Route queries through hybrid retrieval and a reranker without breaking the p95 latency budget.
- Decide when to escalate to an agentic flow and when to answer with classic RAG.
- Score every answer against the evaluation harness and gate deploys on regressions.
- Run inside the customer VPC with no data egress.
This is realistically a multi-team, multi-quarter build. The buy decision usually comes down to whether the time-to-value and risk-adjusted cost of building this in-house beats licensing a platform that already does it. Atolio's case studies (for example, Cribl saved 4 hours per employee per week and cut support tickets by 25%) are the kind of outcome that frames the comparison.
Frequently asked questions
1. What are the biggest enterprise RAG challenges in 2026?
The biggest production-stage challenges are agentic orchestration (one-shot pipelines fail on multi-hop queries), permission enforcement at the index layer, multimodal parsing of charts and tables, cross-encoder reranking for precision, and evaluation with RAGAS or TruLens. Diversity of data sources and chunking remain the foundation, but they are now well-understood. The newer challenges sit on top.
2. What is Agentic RAG and how is it different from traditional RAG?
Traditional RAG follows a linear path: retrieve, then generate. Agentic RAG puts a reasoning agent in front of retrieval. The agent decides which tool or index to query, whether the context is sufficient, and whether to retrieve again before generating. It handles multi-hop questions and cross-system synthesis that linear RAG cannot.
3. When should an enterprise use GraphRAG instead of vector search?
Use GraphRAG when the corpus has entities and relationships that matter (people, products, contracts, events) and when queries require multi-hop reasoning ("How is A connected to B through C?"). For single-fact lookups, vector search with a reranker is usually sufficient. Most mature deployments are hybrid: vectors for breadth, graphs for depth.
4. How do you evaluate a RAG system in production?
Use RAGAS, TruLens, or DeepEval to track faithfulness, answer relevance, context precision, and context recall on a labeled set. Target above 70% context relevance and above 80% faithfulness before shipping to users. Run the harness on every retrieval, prompt, or model change. Add agentic-specific metrics (tool-selection accuracy, decomposition quality) if you have an agent in the loop.
5. How important is a cross-encoder reranker for enterprise RAG?
Most teams find it is the single highest-ROI addition. Practitioner studies report 33% to 40% retrieval accuracy improvement for roughly 120 ms p50 added latency. If you have a production RAG system without a reranker, adding one is usually a higher-impact change than swapping the LLM.
6. How does RAG handle PDFs with charts and tables?
Text-only chunking discards a large fraction of the signal. Multimodal RAG handles this by treating images, page renderings, and structured visuals as retrieval objects. Three patterns dominate: caption-and-index (a vision-language model describes each chart in text), unified vision embeddings (Cohere Embed 4, voyage-multimodal-3.5), and page-as-image with late interaction (ColPali, ColQwen). Most enterprises start with caption-and-index and graduate to unified embeddings.
7. How are permissions enforced in a permission-aware RAG platform?
Permissions are enforced at the index layer at query time, not as a post-filter. ACLs are replicated from each source (SharePoint, Confluence, Google Drive, Slack, Jira), identities are reconciled across systems via the IdP (Okta, Entra ID, Google Workspace, Keycloak), and unauthorized content is excluded before it reaches the user or the model. Permission changes propagate to the index within minutes.
8. Why does deployment in a private cloud matter for enterprise RAG?
For regulated industries (defense, finance, healthcare) and any enterprise with strict data-residency requirements, corporate data cannot leave the customer cloud. A platform that runs only in the vendor's environment is structurally incompatible with these requirements. Self-hosted deployment in the customer's AWS, Azure, GCP, or GovCloud environment, with self-hosted models for the most sensitive use cases, is the only model that clears procurement.
Closing
Enterprise RAG in 2026 looks different from enterprise RAG in 2024. The pipeline became a system. The system became agentic. The agentic system became measurable. The interesting questions are no longer "should we use RAG" or "which embedding model is best." They are: how is your orchestration layer routing queries, how is your permission model enforced, what is your faithfulness score on the eval set, and what does it cost to run this at the scale you actually need.
Most of the pieces are commodities. The integration is not. That is the build-vs-buy calculation, and it is the one most teams underestimate. If the trade-off is worth a conversation, book time with us. Atolio runs in your cloud, with your models, against your permissions, and we have spent the last several years on the integration layer so your team does not have to.