Why Google, Microsoft, and the LLM Giants Won't Win Enterprise Search
It's a reasonable question. Google built the world's most capable search engine. Microsoft has 440 million paid Microsoft 365 subscribers and AI embedded in every product. And then there are the frontier models. OpenAI has 800 million weekly active ChatGPT users. The hyperscalers have the models, the distribution, and the brand recognition.
And yet, the evidence across two decades – and across multiple product generations – points consistently in the other direction. The companies best positioned to win AI-powered enterprise search are precisely the ones with the least incentive to do so.
Here's why.
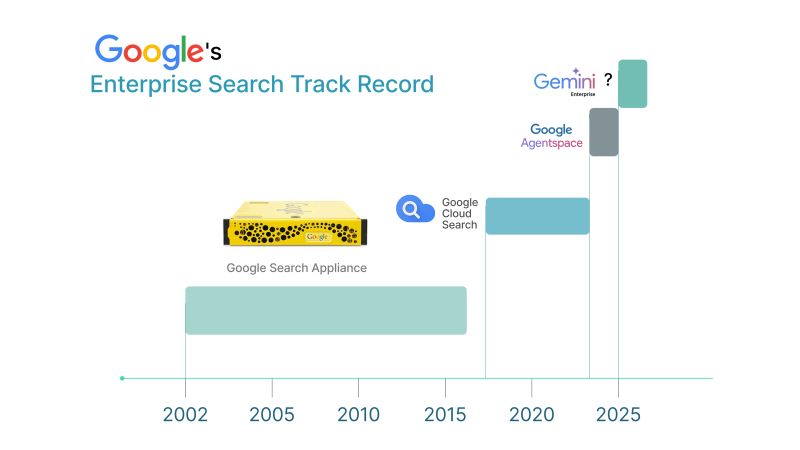
Google's Enterprise Search Track Record: Four Attempts, Zero Wins
Google has tried to crack enterprise search four times. The pattern is worth understanding in detail, because it reveals something structural about how hyperscalers approach markets that are large, but not large enough.
Attempt 1: The Search Appliance (2002 - 2019)
Google's original business plan explicitly included enterprise search as a major revenue driver, the idea being to bring Google-quality search inside the corporate firewall. The product was the Google Search Appliance: a yellow rack-mounted server that was first launched in 2002 and went through several generations before being discontinued in 2019.
For a while, it sold. CIOs in the mid-2000s deployed it widely. But the fundamental problem emerged quickly: Google's internet-inspired ranking algorithms often didn't work well in the messy stew of enterprise information. Website search is not the same thing as enterprise search. The GSA did one thing: it spidered your intranet and applied a simple algorithm. In an era when enterprise knowledge was fragmenting across dozens of systems, that wasn't enough.
Google announced the phase out of the GSA in early 2016 and a complete discontinuation by 2019. Partners who had built businesses around it were given three years' warning. This news hit several appliance-focused Google for Work partners like a ton of bricks.
Attempt 2: Google Cloud Search
The successor was Google Cloud Search: cloud-native, modern architecture, positioned as the next generation. Google Cloud Search, formerly known as Springboard, is focused only on search within G Suite. It never achieved broad adoption as a true enterprise-wide knowledge management platform, and quietly faded from prominence.
Attempt 3: Google Agentspace
Announced at Google Cloud Next in late 2024, Agentspace was flashy. The demo showed unified enterprise search, AI agents, multimodal capabilities, and deep integration across Salesforce, SharePoint, ServiceNow, and Jira. The pitch was compelling: one platform, all your enterprise knowledge, powered by Gemini.
Feedback from practitioners who attempted actual production deployments was considerably more sobering. Partners who tried to get it working in enterprise environments reported significant gaps between what was demoed and what could be deployed.
Attempt 4: Rebranding to Gemini Enterprise
Then came the rebrand. On October 9, 2025, Google Agentspace was renamed to Gemini Enterprise, and starting December 31, 2025, Google Agentspace was no longer available for new subscriptions. Less than a year after launch, the product that was going to solve enterprise search had already been absorbed into a broader platform, making it, at minimum, harder to track, harder to evaluate, and harder to build around.
This is not bad execution. It's a structural pattern. As one analyst noted a decade ago, Google doesn't do corporate customers very well. Google is famous for hiring people with the promise that they will never have to deal directly with persnickety customers. Enterprise search is a category that requires deep customer intimacy, iterative deployment work, and sustained investment in integrations, none of which fits Google's operating model.
The more honest version: if a product isn't going to drive $10 billion or more in revenue, Google's attention drifts. Gmail clears that bar. Enterprise search for a few thousand large organizations does not.
Microsoft Copilot: M365-First by Design
Microsoft's situation is different from Google's, and in some ways more instructive, because the product is genuinely capable and genuinely widely deployed. Microsoft 365 Copilot had approximately 8 million paying subscribers as of August 2025, a 1.8% conversion rate from the total 440 million paid Microsoft 365 users.
The adoption gap is partly a product quality issue. But it's primarily an architecture issue.
The Graph Problem: First-Class for M365, Second-Class for Everything Else
Microsoft Copilot is built on the Microsoft Graph, a unified API that gives the model access to your Microsoft 365 data: Outlook, Teams, SharePoint, OneDrive, Planner. Within that ecosystem, Copilot is genuinely capable. It understands relationships between documents, meetings, emails, and people. It is, within the M365 world, a first-class enterprise knowledge platform.
The problem is that most enterprise data doesn't live in M365. It lives in Salesforce, Jira, Confluence, Slack, ServiceNow, Workday, custom databases, and dozens of other systems. For those, Microsoft offers Graph Connectors, a mechanism that ingests external content into the Microsoft Graph as externalItem blobs.
The architectural limitation of this approach is significant. While internal M365 permissions are observed when interacting with the semantic index's standard M365 content, external system permissions are NOT directly retained. Instead, an admin must configure who can see the data brought into the semantic index for each external data source. Permission-aware retrieval, one of the foundational requirements of enterprise search, is a solved problem for M365 data and an administrative burden for everything else.
The result is what the comparison diagram makes plain: the Microsoft Graph has deep, first-class relationships across M365 data. External data gets a semantic index for search and grounding, but without the full graph relationships that make M365 content so powerful. Copilot connectors add searchable text and basic metadata. Deep cross-app reasoning across non-Microsoft tools is limited.
Gartner interviewed Microsoft Copilot enterprise customers and found that only 5% of organizations moved from a pilot to larger-scale deployments. Two out of three senior managers at B2B organizations surveyed by TechRadar said they are not prioritizing investing in Copilot in 2025.
The reason is rarely that Copilot doesn't work for M365. The reason is that enterprises don't run exclusively on M365 – and the moment you step outside that ecosystem, the knowledge management capability degrades significantly.
The Ecosystem Tax
There's a deeper issue worth naming. Microsoft's enterprise AI strategy is fundamentally an M365 retention strategy. Copilot is an exceptionally compelling reason to stay on Microsoft's productivity stack, to add Microsoft 365 seats, and to route more of your enterprise workflow through Microsoft-controlled systems. That's rational from Microsoft's perspective. But it is also not neutral infrastructure.
For organizations whose data estate extends significantly beyond M365 – and most enterprise data estates do – Copilot is not truly enterprise-wide AI-powered search. It is M365-optimized AI search with connectors for everything else.
Why LLM Providers Won't Solve This Either
The frontier model providers (OpenAI, Anthropic, Google DeepMind) are building increasingly capable general-purpose models. They are not building enterprise search platforms.
The distinction matters. Enterprise RAG is not a model problem. It is a data pipeline problem, a permission management problem, a connector engineering problem, and a deployment architecture problem. Knowing how to answer questions is different from knowing how to securely retrieve the right documents from fourteen different enterprise systems, apply permission-aware filtering based on the user's role, and synthesize an answer that reflects the actual state of enterprise knowledge.
OpenAI's push into enterprise search is the most serious challenge from an LLM provider to date, and it's instructive precisely because of where it falls short.
OpenAI's "Company Knowledge" feature, launched in late 2025, lets ChatGPT Enterprise users connect workplace apps like Slack, SharePoint, and Google Drive and receive answers grounded in internal content with citations. It respects existing permissions. It has a growing connector library. On paper, it's a credible enterprise knowledge management play.
But look at the technical documentation, and the structural limits become clear.
The Data Residency Problem Is Not Solved
OpenAI expanded data residency options at the end of 2025, allowing eligible enterprise customers to store data at rest in regions including Europe, the UK, Japan, Canada, and others. The announcement was widely covered as a compliance breakthrough.
What received less coverage: the expansion applies only to data that is stored or at rest, not to data being used for inference by a model, whose default location continues to be the US. The moment a user sends a query, the prompt is temporarily processed on US-based infrastructure before the result is sent back.
For organizations subject to strict data sovereignty requirements – where the legal question isn't just where data rests, but where it is processed – this is not a compliance solution. It is a partial one. And the connector situation is worse: for all apps with sync other than Google Drive and GitHub, the synced search index is stored in OpenAI's US Azure data centers. Apps with sync like Google Drive and SharePoint are supported for customers based in the US with data residency enabled, or those who have not elected for data residency at-rest.
In other words: a European enterprise that has specifically elected data residency to comply with GDPR cannot use some of ChatGPT's most important enterprise connectors at all. The very customers who most need compliant enterprise search are the ones excluded from the full product.
The Knowledge Graph Gap
There's a deeper architectural issue. Modern enterprise search derives much of its value not from retrieval alone, but from understanding the relationships between information: who owns a document, which project a conversation relates to, how a Jira ticket connects to a Slack thread and a Google Doc. This is the function of a knowledge graph.
While Glean, Slack, and Gemini all have a knowledge graph at their foundation, OpenAI makes no mention of a knowledge schema or graph at company knowledge's core. Knowledge graphs can conduct entity-aware searches, meaning a search for a person's name will acknowledge the person as an entity and not just as a name to be found in documentation. They also aid in disambiguation and relationship queries. Without a graph layer, Company Knowledge is fundamentally a retrieval system – a capable one, but not a context-aware enterprise knowledge platform in the fullest sense.
General-Purpose AI Is a Different Business
The more fundamental issue is one of strategic focus.
Enterprise search is a focused, deployment-intensive, customer-intimate category. It requires sustained investment in connectors, permission management, relevance tuning, and integration engineering for the specific, messy reality of how enterprise data actually lives across dozens of systems. That work is unglamorous and doesn't generate the kind of consumer press that image generation or voice mode does.
OpenAI, by contrast, positions ChatGPT as a general-purpose AI assistant where company knowledge sits alongside coding, content creation, data analysis and image generation.
LLM providers are in a race to the bottom on inference pricing – a dynamic that's good for buyers who haven't locked in, and largely irrelevant to enterprise search architecture. An organization that pipes its Jira tickets, Slack messages, and product roadmaps into a frontier model API has built a system with unresolved data sovereignty questions, no native permission enforcement, and a single-model dependency that reprices every few months.
The organizations that actually solve enterprise knowledge management are doing something orthogonal to model capability: they're building the infrastructure layer underneath the model (the connectors, the permission-aware retrieval system, the enterprise RAG pipeline) and making the model itself interchangeable.
The Structural Reason Specialists Win This Category
The enterprise search market is valued at $7.47 billion in 2026 and growing at a 9.31% CAGR. The fastest-growing drivers are retrieval-augmented generation adoption, conversational AI search, and the pressure from data sovereignty mandates that are reshaping how enterprises think about where their data can go.
None of these dynamics favor the hyperscalers.
Data sovereignty requirements – which are driving on-prem, self-hosted, and airgapped AI deployments across regulated industries – are structurally incompatible with cloud-first, ecosystem-first products like Copilot and Gemini Enterprise. A government agency or a defense contractor cannot route its sensitive queries through Microsoft's Graph or Google's cloud infrastructure. A European enterprise subject to strict data residency laws cannot accept an architecture where non-M365 data "may be processed in the US, EU, or other regions."
The winning architecture for enterprise search is model-agnostic, deployment-flexible, and organization-wide in scope, not M365-scoped, not Google-cloud-dependent, and not rebuilt from scratch every eighteen months when the hyperscaler decides the product needs a new name.
Atolio's platform deploys the full enterprise search stack (connectors, search engine, enterprise RAG pipeline, LLM orchestration) inside the customer's own environment. It's permission-aware, context-aware, and model-agnostic by design. It doesn't care whether you're on AWS, Azure, or GCP, or whether you're running on-premises. And because it indexes across all your systems simultaneously rather than treating M365 as first-class and everything else as an externalItem blob, it actually reflects how enterprise knowledge works.
The question "Won't Google just solve this?" has a twenty-year data trail behind it. The answer, consistently, is no – not because Google lacks the capability, but because winning this category requires the kind of sustained, customer-intimate, deployment-focused commitment that hyperscalers are structurally not built to deliver.
Build on Infrastructure Built for Enterprise
If your organization's knowledge lives across more systems than Microsoft 365, or if your compliance requirements mean your data cannot route through a hyperscaler's cloud, Atolio's self-hosted enterprise search platform is built for exactly this situation.
Truly universal scope. Your environment. Your LLM choice. Permission-aware retrieval across every system you use.
More on how Atolio approaches enterprise knowledge management here.