The AI-Native Data Stack Is Right. The Deployment Model Is Wrong.
Tomasz Tunguz of Theory Ventures recently published a sharp piece on "The Postmodern Data Stack is AI." His core argument: the modern data stack's ETL-to-warehouse-to-semantic-layer-to-BI pipeline, which created more than $100 billion in market cap over the past decade, was optimized for structured numerical data. But AI changes the equation. Enterprises now need to query unstructured data, including call transcripts, PDFs, Slack conversations, and strategy documents, at scale. The semantic layer must now combine structured and unstructured information simultaneously, because all of it feeds AI and powers agents. Tunguz argues that AI tools querying distributed systems directly is faster, more flexible, and requires fewer data engineers than the old centralized warehouse approach.
The architectural argument is correct. One question it leaves unanswered is the one enterprises hit first in every procurement conversation: where does this stack actually run?
For a significant share of the global enterprise market, that question is not a preference. It is the entire evaluation.
What Changes When AI Can See Everything
The original modern data stack was primarily about structured data: revenue figures, product metrics, customer counts. The risk profile of centralizing that data in a cloud warehouse, while never trivial, was bounded. A breach exposed tables of numbers.
The postmodern stack Tunguz describes is categorically different. It ingests and queries the full corpus of enterprise knowledge: CEO emails, board materials, Salesforce opportunity data, Slack conversations, unreleased product roadmaps, unfiled patents, competitive strategy documents. The semantic layer now sits on top of everything that matters.
This is not a modest expansion of the attack surface. It is the creation of the most sophisticated data aggregation risk most enterprise security teams have ever been asked to review. When you build this stack inside a vendor's cloud, you have effectively handed a single third party the keys to every system your organization runs.
The 2024 National Public Data breach is the clearest illustration of where data aggregation risk leads. According to research published by SecurityInfoWatch and Kiteworks, the breach exposed 2.9 billion records and demonstrated how data aggregation creates concentrated risk points where a single security failure can have global consequences. National Public Data's business was data aggregation. One breach, one point of failure, and the downstream consequences were global. The postmodern enterprise AI stack is, structurally, a data aggregation business running inside your organization. The same logic applies.
Supply chain and third-party risk are now the dominant breach vector. Supply chain attacks via a third-party vendor or software dependency have surged, now causing roughly 30% of breaches. The Drift and Salesforce incident documented in Reco's 2025 AI and Cloud Security Breaches report makes the mechanism explicit: a compromised GitHub account led to Drift's AWS environment, where attackers extracted OAuth tokens and used custom scripts to query customer Salesforce instances and exfiltrate contacts, opportunities, and cloud credentials. One integration became a doorway into everything connected to it.
That is the risk profile of a SaaS-hosted AI knowledge platform. Not theoretical exposure. An actual attack chain.
The AI Governance Gap Is Wide and Getting Wider
What makes the deployment question more urgent is how poorly most enterprises currently govern the AI tools they have already deployed. Just a sampling of examples:
According to IBM's 2025 Cost of a Data Breach Report, based on data from 600 organizations globally:
- 97% of organizations that experienced breaches of AI models or applications reported lacking proper AI access controls.
- 63% of breached organizations either do not have an AI governance policy or are still developing one.
- One in five organizations reported a breach attributable to shadow AI.
Another report drawing on more than 1.2 billion blocked transactions found that AI tools like ChatGPT and Microsoft Copilot contributed to 4.2 million data loss violations in 2024, revealing how personal identifiers, intellectual property, and financial data are routinely exposed. Varonis research found that 90% of organizations have sensitive files exposed through Microsoft 365 Copilot, with an average of 25,000 or more sensitive folders accessible to anyone who asks the right prompt. In Salesforce environments, 100% of deployments have at least one account capable of exporting all data.
About 8.5% of employee prompts to large language models contain sensitive information that could put organizations at risk. Multiply that by the number of daily queries in a large enterprise and the exposure is not edge-case. It is routine.
Against this backdrop, the regulatory response is also accelerating. U.S. agencies issued 59 AI regulations in 2024, more than double the previous year. GDPR, CCPA, and HIPAA all carry specific requirements around audit trails, data deletion, and processing records that SaaS AI architectures frequently cannot satisfy. IBM found that 32% of breached organizations paid regulatory fines, with 48% exceeding $100,000.
You Cannot Bolt Security onto a SaaS Architecture
The standard enterprise response to these risks has been a combination of contractual protections, vendor security reviews, and data processing agreements. These are necessary, but they are not sufficient.
The reason is architectural. When your AI knowledge platform runs in a vendor's cloud, the security boundary is the vendor's security boundary. Your governance policies, your access controls, your audit logging capabilities are all downstream of infrastructure you do not control. A breach of that vendor's infrastructure is a breach of your entire knowledge corpus. The sophistication of your internal security posture is irrelevant once the data has left the perimeter.
This is precisely the dynamic that makes supply chain attacks so effective. Third-party risk management remains the least mature security domain in 2024, creating a systematic vulnerability that threat actors increasingly target. Supply chain dependencies create force multiplier effects, where the impact extends far beyond the directly compromised organization.
Security cannot be a feature added to a SaaS deployment. It has to be the starting point of the architecture.
The Postmodern Stack, Deployed Correctly
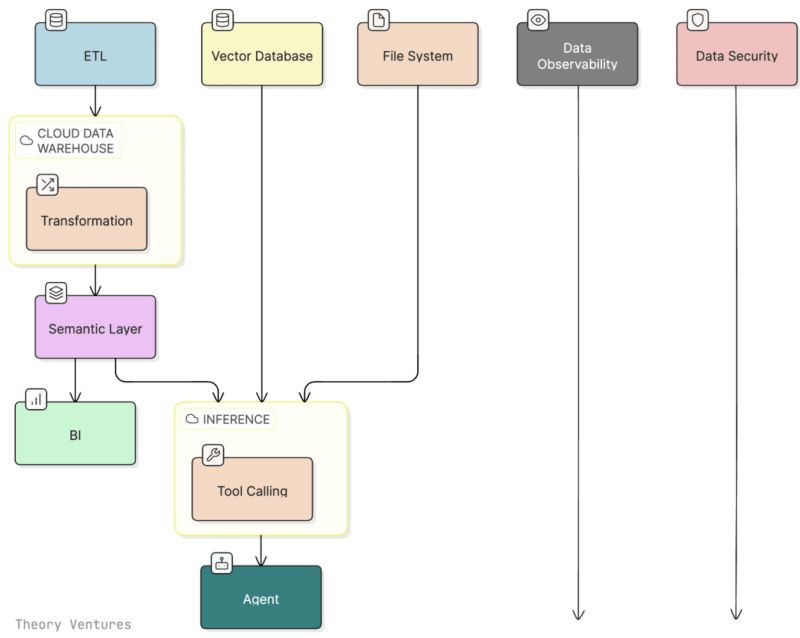
Tunguz's postmodern data stack diagram, reproduced in Theory Ventures' January 2026 post, shows the architecture clearly: ETL, vector database, file system, and inference layer feeding into an agent, with data observability and data security as spanning concerns running across the entire stack. The observability and security columns in that diagram are not modules. They are the conditions under which everything else operates.
The AI-native architecture is right. The inference layer querying distributed systems directly rather than waiting for centralized warehouse processing is right. The agent as the output layer that synthesizes across structured and unstructured data is right.
The deployment model that makes this architecture usable for enterprises with real security requirements is self-hosted, on-premises, or deployed within the customer's own VPC. Not because the technology requires it, but because the risk profile of the data the postmodern stack now touches demands it.
Atolio's enterprise search platform deploys the full stack, connectors, vector search index, enterprise RAG pipeline, LLM orchestration, inside the customer's own environment. The entire architecture Tunguz describes runs within your trust boundary. Observability and security are not bolted on. They are built into the deployment model from the start because the deployment model is the security model.
When the semantic layer now covers everything that matters, where it runs is not a deployment preference. It is the security decision.
Build the Postmodern Stack – And Own the Infrastructure It Runs On.
The enterprises that will capture the full productivity value of the AI-native data stack are the ones that refuse to make a tradeoff between capability and security. The architecture and the deployment model are separable. You can have both.