Context Is Not a Feature of Enterprise AI. It's the Entire Foundation.
Everyone is racing toward enterprise AI agents. Autonomous workflows. Instant answers. AI that takes action on your behalf across every system your organization runs on.
Almost nobody has secured the foundation those agents require to actually work.
That foundation is context. Not "context" in the casual sense of knowing what topic a conversation is about, but context in the deep, structural sense: who is asking, what they have access to, what projects they're on, who they work with, what has happened across all their systems in the past six months. The complete organizational picture that makes a retrieved answer relevant rather than merely accurate.
Get the model right and skip the context layer, and you get an agent that confidently answers the wrong question. The research on this is unambiguous. And the architectural implications for how enterprises should build and evaluate AI search and agent platforms are significant.
Why PageRank Doesn't Work Inside Your Company
Before Atolio was built, the team interviewed 762 enterprise leaders – more than 100 from the Fortune 1000 – and asked a simple question: why did past enterprise search rollouts fail?
The answer pointed to a single root cause that most vendors never address.
Google's search algorithm, which shaped an entire generation of enterprise search thinking, was built for the open web. Relevance on the open internet is determined largely by links. The more inbound links a page has, the more it is trusted. The more it is trusted, the higher it ranks. PageRank is an elegant solution to a world where documents cite each other constantly.
That world does not exist inside companies. A Word document doesn't link to the PDF it references. A Jira ticket doesn't cite the Salesforce record it relates to. A Slack thread rarely names the Confluence page that seeded the conversation. The link graph that underpins consumer search simply isn't there.
When vendors attempt to apply the same logic to enterprise data, they fail because there are too few signals to rank results meaningfully. This is why internal search has been broken for the better part of 20 years, not because the technology wasn't good enough, but because the signal model was wrong from the start.
The Social Graph as the New PageRank
The enterprise may not have a link graph, but it has something equally powerful: a social graph.
Documents may not link to documents, but people talk to people. People edit documents, assign tickets, attend meetings, review code, and send messages. Every one of those interactions is a signal about relevance, about what matters to whom, and in what context.
This points to two overlapping layers of context that, combined, enable retrieval that is fundamentally different from keyword matching:
- User context: who you are, what projects you're on, who you collaborate with most closely, what you've accessed recently.
- Organizational context: where your team sits in the company structure, what documents your immediate circle has created and edited, what the people adjacent to your role care about.
Layered together, these signals allow an enterprise search platform to rank results by relevance to the specific person asking, not just by relevance to the words in the query. If a VP of Sales and a VP of Engineering both search "Q3 Roadmap," the correct result is different for each of them. Traditional keyword search returns the same results to both and hopes for the best. Context-aware retrieval understands who is asking and adjusts accordingly.
This is the thesis Atolio was built on, and the 762 enterprise interviews validated it: the crown jewels of corporate knowledge flow through people, not links. You cannot solve enterprise search without solving identity first.
What the Research Says About Context and Agent Reliability
This is not a proprietary insight unique to Atolio. The academic and analyst literature on enterprise AI agents has converged on the same conclusion from multiple directions.
Anthropic's own engineering team, writing about the architecture of effective AI agents, describes the challenge precisely: given that LLMs are constrained by a finite attention budget, good context engineering means finding the smallest possible set of high-signal tokens that maximize the likelihood of some desired outcome. The problem is not making the context window bigger. It is putting the right information into it.
This matters more than most enterprise AI buyers realize. In July 2025, Chroma Research tested 18 state-of-the-art models and found what they called "context rot:" performance degrades at every context length increment, not just near the limit. Simply stuffing more documents into a longer context window does not produce better answers. It produces slower, noisier, less reliable ones. The solution is precision retrieval: getting exactly the right context to the model, not more of it.
The stakes of getting this wrong are significant. OpenAI and Georgia Tech researchers proved in 2025 that hallucinations are mathematically inevitable in LLMs without grounding. This isn't a quality issue that better models will eventually solve. It is a structural property of how LLMs work. Without verified organizational context, even the most capable frontier model will generate confident, fluent, wrong answers.
The numbers on grounding are compelling. RAG-based retrieval reduces hallucinations by 40-71% across benchmarks. In enterprise deployments, organizations report 70-90% fewer hallucinations with proper context infrastructure. Context is the primary lever for making enterprise AI reliable, not model scale.
From Retrieval to Context Engine: How the Architecture Is Evolving
The industry's understanding of what enterprise RAG actually needs to be is maturing rapidly.
All agent data access needs – whether existing unstructured documents via RAG, real-time generated interaction logs via memory, or structured service interfaces – can be unified, governed, and accessed within an integrated platform. This platform is precisely what the industry now calls a Context Engine or Context Platform. It is no longer an isolated retrieval tool but infrastructure providing comprehensive, intelligent context assembly services for AI applications.
This framing matters because it changes what enterprises should be evaluating when they assess AI-powered enterprise search platforms. The question is no longer "how good is the search?" It is: does this platform function as a context engine, one that assembles, governs, and delivers the right organizational context to every query and every agent action?
The traditional view of RAG as "retrieve documents, stuff them into context, generate answer" is obsolete. Successful enterprise deployments treat RAG as a knowledge runtime: an orchestration layer that manages retrieval, verification, reasoning, access control, and audit trails as integrated operations. The analogy to Kubernetes is apt, just as container orchestration manages workloads with health checks and security policies, a knowledge runtime manages information flow with retrieval quality gates and governance controls embedded into every operation.
In an empirical study of AI agent-powered RAG deployments across research, education, and biomedical domains, engineers documented seven recurring failure points including failure to retrieve documents, failure to include correct chunks in context, and generation errors despite having the right retrieved data and inputs. These failures arise even in carefully engineered pipelines. They are almost entirely failures of context assembly, not failures of model capability.
The Permission Layer Is Not Optional
Context has another dimension that often gets treated as a compliance detail but is architecturally central: permission-awareness.
Enterprise knowledge is not flat. Different people are authorized to see different information. A sales rep should not see an engineer's performance review. A contractor should not see board materials. When a context engine surfaces information without enforcing the permissions that govern it, it doesn't just create a compliance risk: it corrupts the relevance of the answers it produces.
Build permission checks into retrieval, not just the UI. Treating embeddings as enough is a critical mistake. Use vectors and graph constraints, as hybrid beats either alone for enterprise precision. This is the difference between a system that looks permission-aware and one that actually is. Applying access controls at the interface layer while ignoring them during retrieval means the model sees – and reasons over – content the user is not supposed to access. The answer may be filtered before display, but the grounding has already been compromised.
For regulated enterprises (e.g. financial services, insurance, legal services, healthcare, defense, government) this is not an edge case. It is the primary evaluation criterion. A context engine that cannot enforce permission-aware retrieval at the data layer is not deployable in those environments, regardless of how capable the model is on top of it.
This is also why the deployment architecture of the platform underneath the context engine matters. 40-60% of RAG implementations fail to reach production due to retrieval quality issues, governance gaps, and the inability to explain decisions to regulators. The organizations that make it to production are the ones that treat knowledge infrastructure as a first-class architectural concern from the beginning, not a layer bolted on after the model is already running.
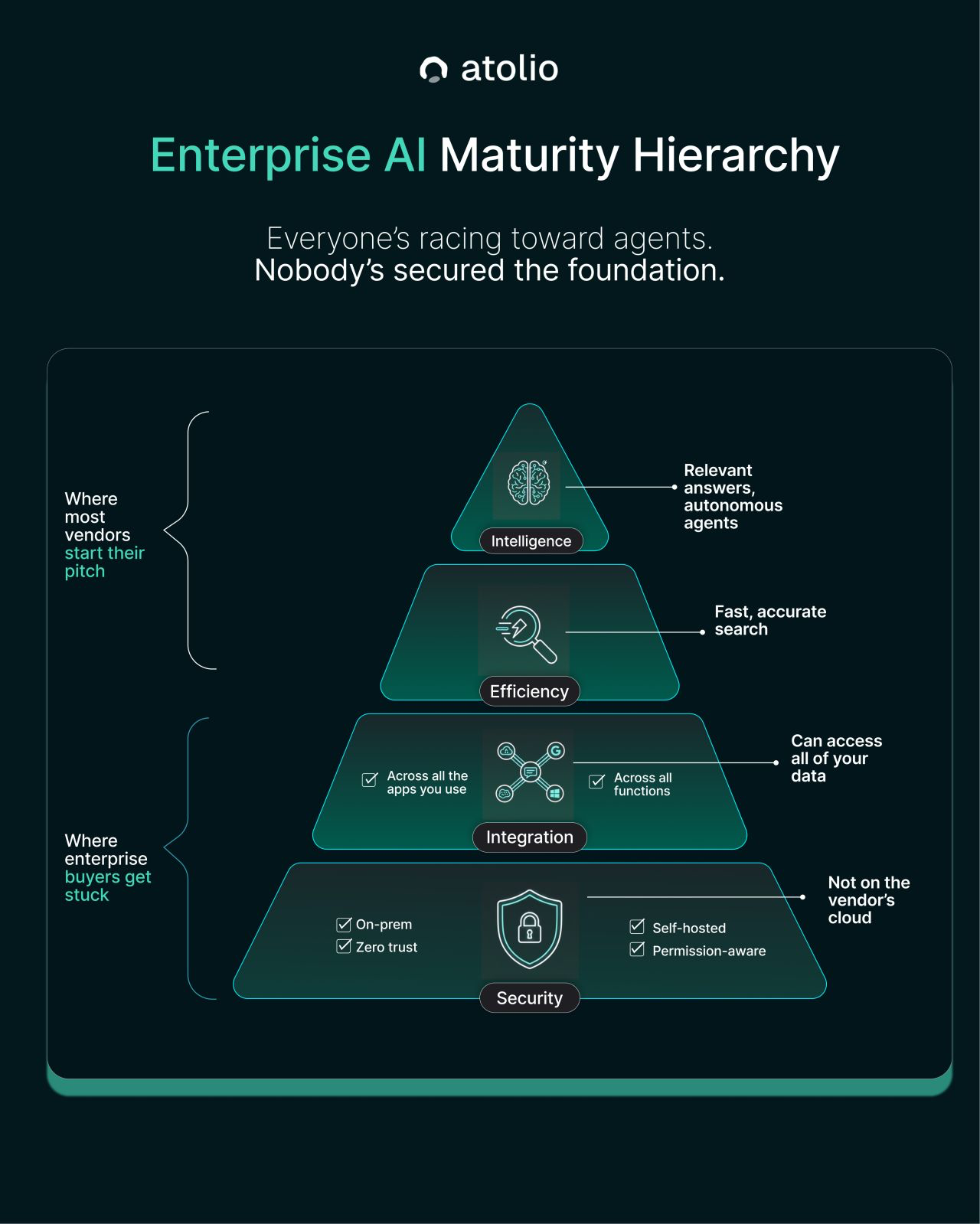
This sequencing has a practical implication that most enterprise AI buyers discover too late: you cannot shortcut to the top.
Most vendors start their pitch at Intelligence: autonomous agents, synthesized answers, autonomous workflows. The demos are genuinely compelling. The gap between demo and production is where enterprises get stuck, because two foundational layers were never properly built before anyone started pitching the intelligence layer.
The first is Security. On-premises deployment, zero trust architecture, self-hosted infrastructure, permission-aware retrieval at the data layer rather than the interface layer. Without this, sensitive data is exposed, regulated industries cannot deploy at all, and the context the agent is reasoning over cannot be trusted. A context engine with a compromised security layer is not a foundation. It is a liability.
The second is Integration: genuine, universal connectivity across all the systems an organization actually uses. Not first-class support for one vendor's ecosystem and metadata blobs for everything else. The context engine is only as complete as the data it can reach. An agent that cannot see six of your fourteen systems is not an enterprise AI agent. It is a well-dressed island.
Only when those two layers are solid does Efficient, accurate search become reliably achievable. And only when search is working does the Intelligence layer – agents, reasoning, autonomous action – deliver what the demos promise.
The difference between organizations capturing real value from enterprise AI and those still cycling through pilots is almost always the same thing: whether they treated context infrastructure as the foundation or as an afterthought. The right data, the right security controls, the right integration breadth, delivered to the right person. That is what agents run on. Everything else is a demo.
The difference between organizations capturing value from enterprise AI and those still waiting? Context infrastructure. The right data, delivered to the right agent, governed by the right policies, with the right security controls.
Everyone is racing toward agents. The organizations that will actually benefit from them are the ones investing in the foundation first.
Build the Foundation. Then Build the Agents.
Atolio's enterprise search platform is architected as a context engine from the ground up: permission-aware retrieval across all your systems, deployed inside your own environment, with identity and organizational context as first-class signals rather than afterthoughts.
The intelligence layer gets smarter as the context layer gets richer. That sequence is not arbitrary. It is the only order that works.